python pairplot 그리기
python pairplot 그리는 법을 상세히 소개하려 합니다.
해당 코드를 실습할수 있는 데이터는
캐글 데이터 페이지를 통해서 다운로드 부탁드리겠습니다.
import warnings
warnings.filterwarnings(action='ignore')
import numpy as np
import pandas as pd
from pandas import DataFrame
import seaborn as sns
%matplotlib inline
import matplotlib.pyplot as plt
data = pd.read_csv("2019_kbo_for_kaggle_v2.csv")
data['YOPS']=data['YOPS'].fillna(0.00000)
print(data.shape)
data.head()
(1913, 37)
| batter_name | age | G | PA | AB | R | H | 2B | 3B | HR | ... | tp | 1B | FBP | avg | OBP | SLG | OPS | p_year | YAB | YOPS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 백용환 | 24.0 | 26.0 | 58.0 | 52.0 | 4.0 | 9.0 | 4.0 | 0.0 | 0.0 | ... | 포수 | 5.0 | 6.0 | 0.173 | 0.259 | 0.250 | 0.509 | 2014 | 79.0 | 0.580 |
| 1 | 백용환 | 25.0 | 47.0 | 86.0 | 79.0 | 8.0 | 14.0 | 2.0 | 0.0 | 4.0 | ... | 포수 | 8.0 | 5.0 | 0.177 | 0.226 | 0.354 | 0.580 | 2015 | 154.0 | 0.784 |
| 2 | 백용환 | 26.0 | 65.0 | 177.0 | 154.0 | 22.0 | 36.0 | 6.0 | 0.0 | 10.0 | ... | 포수 | 20.0 | 20.0 | 0.234 | 0.316 | 0.468 | 0.784 | 2016 | 174.0 | 0.581 |
| 3 | 백용환 | 27.0 | 80.0 | 199.0 | 174.0 | 12.0 | 34.0 | 7.0 | 0.0 | 4.0 | ... | 포수 | 23.0 | 20.0 | 0.195 | 0.276 | 0.305 | 0.581 | 2017 | 17.0 | 0.476 |
| 4 | 백용환 | 28.0 | 15.0 | 20.0 | 17.0 | 2.0 | 3.0 | 0.0 | 0.0 | 0.0 | ... | 포수 | 3.0 | 3.0 | 0.176 | 0.300 | 0.176 | 0.476 | 2018 | 47.0 | 0.691 |
5 rows × 37 columns
from matplotlib import rc
import platform
if platform.system() == 'Windows':
rc('font', family='Malgun Gothic')
elif platform.system() == 'Darwin': # Mac
rc('font', family='AppleGothic')
else: #linux
rc('font', family='NanumGothic')
plt.rcParams['axes.unicode_minus'] = False
먼저 기본적인 틀 입니다.
PairGrid는 주어진 데이터 컬럼에 대한 모든 조합을 만들어주는 빈 틀을 위한 코드라고 보시면 됩니다.
여기서 corner=True를 설정하시면 위쪽이 없는 삼각형의 모양으로 나오게 됩니다.
단 이 설정을 하게 되면 첫 컬럼인 age 컬럼이 입력되어 있지 않습니다.
이러한 case가 생기기 때문에, 이는 다른 함수 설정을 통해서 살리는 방법을 나중에 소개하도록 하겠습니다.
temp = data[['age','HR','war','YAB','YOPS']]
g = sns.PairGrid(temp, diag_sharey=False, corner=True)
g.fig.suptitle("pair plot 그리기", x=0.25, y=1.02, size=20)
Text(0.25, 1.02, 'pair plot 그리기')
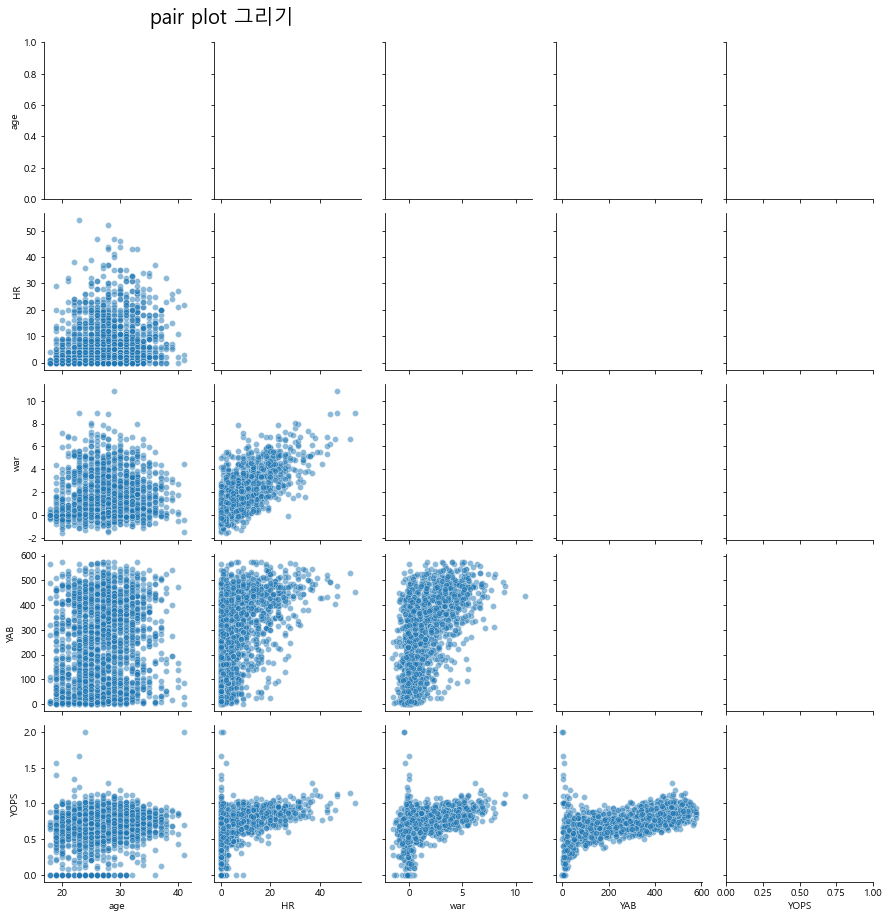
이러한 빈 틀에다가 하단, 상단, 중앙을 나눠서 각각 그림을 채워 넣을 수 있습니다.
먼저 아래쪽은 map_lower를 통해서 지정할 수 있으며
하단에 scatter plot을 그려보도록 하겠습니다.
temp = data[['age','HR','war','YAB','YOPS']]
g = sns.PairGrid(temp, diag_sharey=False)
g.fig.suptitle("pair plot 그리기", x=0.25, y=1.02, size=20)
g.map_lower(sns.scatterplot, data=temp, alpha=0.5)
<seaborn.axisgrid.PairGrid at 0x1ac527efa00>
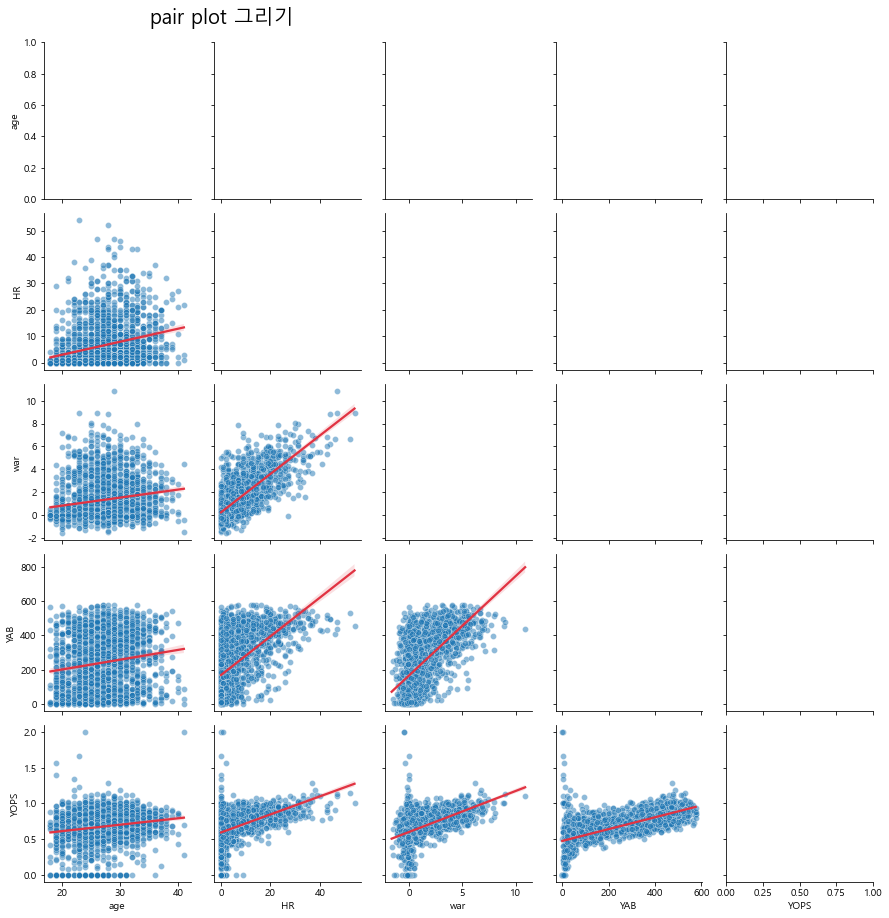
그리고 이 pairgrid 안에서는 같은 영역이라도 중첩해서 그리는 것이 가능합니다.
그럼 먼저 하단에 scatter plot을 그리고
scatter plot을 제외한 상관관계선을 추가한 그래프를 그려보겠습니다.
temp = data[['age','HR','war','YAB','YOPS']]
g = sns.PairGrid(temp, diag_sharey=False)
g.fig.suptitle("pair plot 그리기", x=0.25, y=1.02, size=20)
g.map_lower(sns.scatterplot, data=temp, alpha=0.5)
g.map_lower(sns.regplot, data=temp, scatter=False, color=sns.color_palette("rocket")[3])
<seaborn.axisgrid.PairGrid at 0x1ac535dc700>
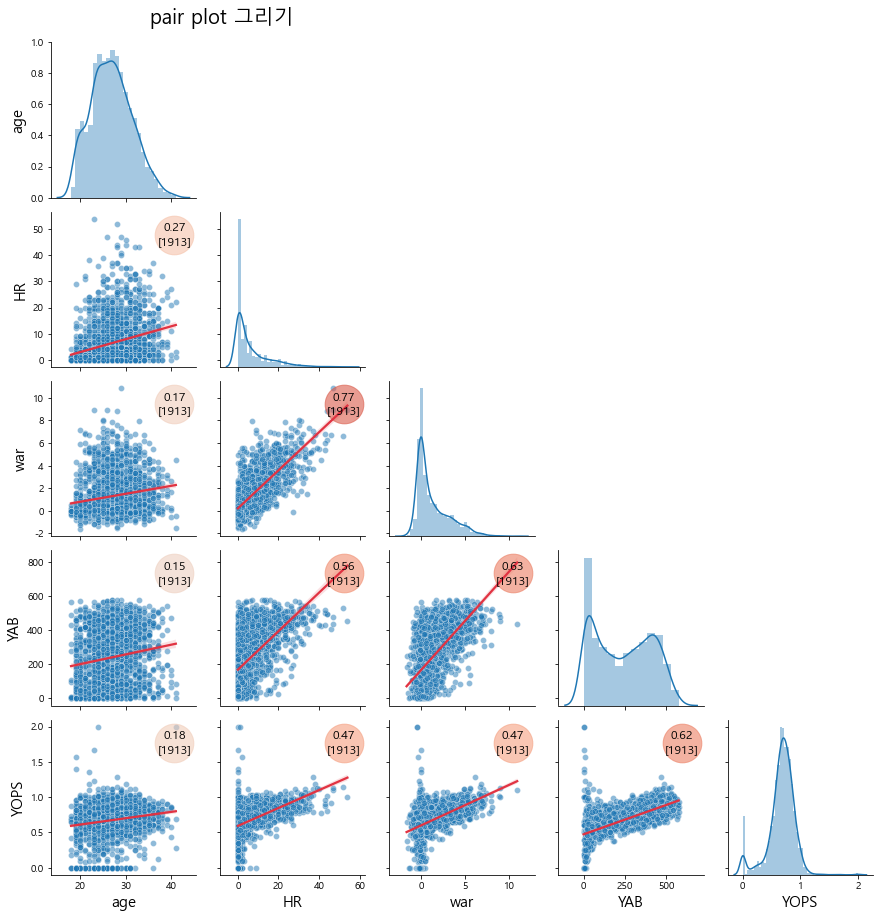
추가로 각 컬럼간의 상관관계와 해당 두 컬럼이 중첩되는 갯수를 계산해서
이를 텍스트로 입력 하는 함수를 구현해보겠습니다.}
def corrdot(*args, **kwargs):
temp2 = DataFrame([args[0], args[1]]).T #두 컬럼을 dataframe화
#텍스트를 강조하기 위한 원 만들기
ax = plt.gca()
marker_size = 1500 #원 사이즈
corr_r = args[0].corr(args[1], 'pearson') #각 컬럼간 상관관계 구하기
ax.scatter([.85], [.85], marker_size, [corr_r], alpha=0.6, cmap="coolwarm",
vmin=-1, vmax=1, transform=ax.transAxes)
#원 안에 넣을 텍스트 만들기, corr 값 입력 및 두 컬럼 중 na가 하나라도 있는 것을 제외함
corr_text = f"{corr_r:2.2f}" + "\n" + "[" + str(temp2.dropna().shape[0]) + "]"
#안에 넣을 텍스트를 삽입
font_size = 12
ax.annotate(corr_text, [.85, .85,], xycoords="axes fraction",
ha='center', va='center', fontsize=font_size)
temp = data[['age','HR','war','YAB','YOPS']]
g = sns.PairGrid(temp, diag_sharey=False)
g.fig.suptitle("pair plot 그리기", x=0.25, y=1.02, size=20)
g.map_lower(sns.scatterplot, data=temp, alpha=0.5)
g.map_lower(sns.regplot, data=temp, scatter=False, color=sns.color_palette("rocket")[3])
g.map_lower(corrdot)
<seaborn.axisgrid.PairGrid at 0x2b12141cb50>
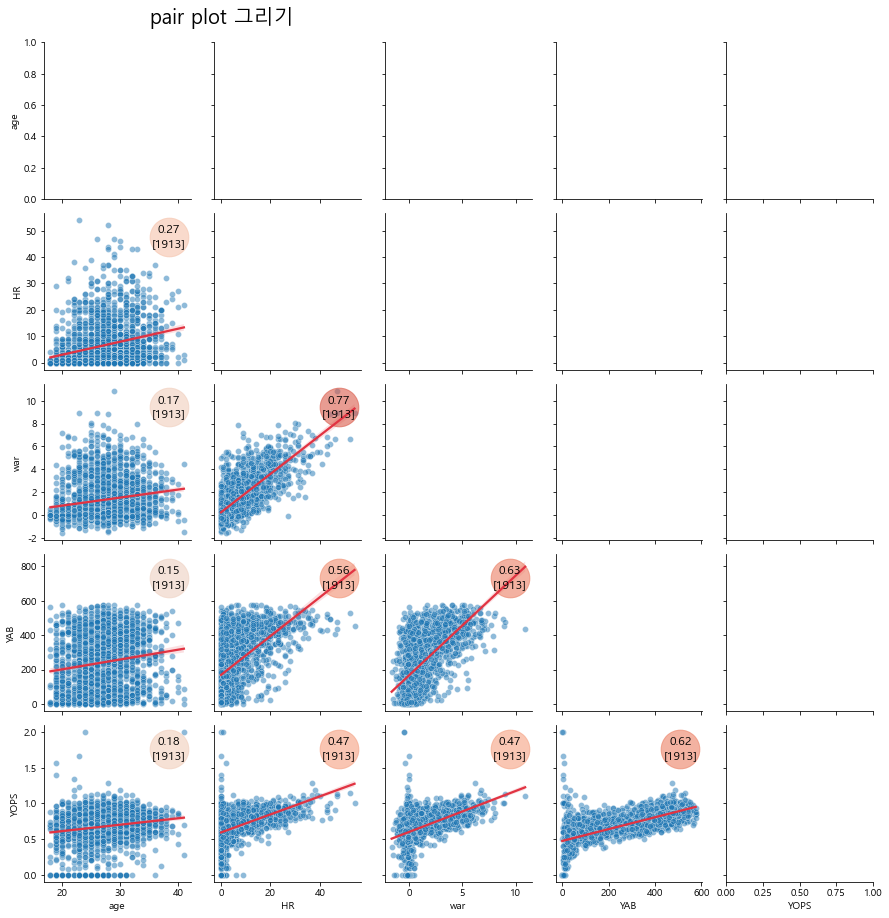
원래는 pairgrid에 corner를 통해서 위쪽을 지우는 방식이 있습니다만,
처음에 언급 드렸다시피 첫 번째 컬럼이 표기가 되지 않는 점이 있었습니다.
그리고 상단, 하단, 중간을 사용자가 지정해서 지울수 있게
해당 영역을 지우는 함수를 작성하고 이번에는 하단을 지워보도록 하겠습니다.
def hide_current_axis(*args, **kwds):
plt.gca().set_visible(False)
temp = data[['age','HR','war','YAB','YOPS']]
g = sns.PairGrid(temp, diag_sharey=False)
g.fig.suptitle("pair plot 그리기", x=0.25, y=1.02, size=20)
g.map_upper(sns.scatterplot, data=temp, alpha=0.5)
g.map_upper(sns.regplot, data=temp, scatter=False, color=sns.color_palette("rocket")[3])
g.map_upper(corrdot)
g.map_lower(hide_current_axis)
<seaborn.axisgrid.PairGrid at 0x1ac575b6160>
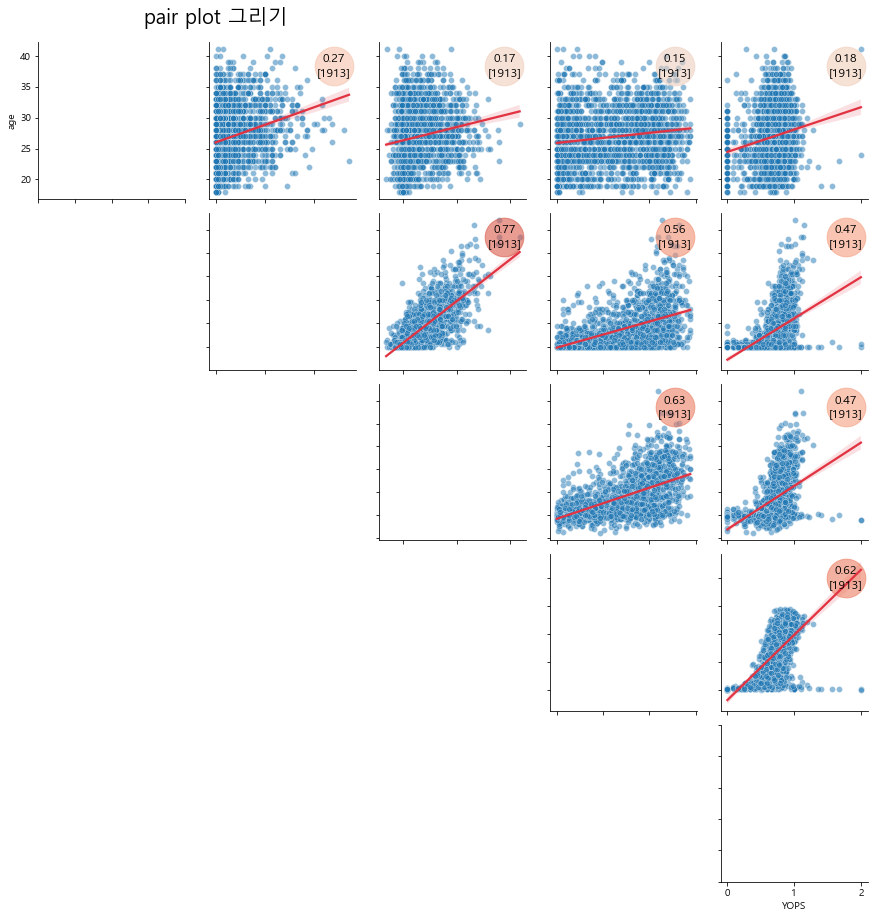
가운데 영역은 map_diag를 통해서 사용이 가능하며
주로 histogram 혹은 distplot을 넣는 영역입니다.
temp = data[['age','HR','war','YAB','YOPS']]
g = sns.PairGrid(temp, diag_sharey=False)
g.fig.suptitle("pair plot 그리기", x=0.25, y=1.02, size=20)
g.map_lower(sns.scatterplot, data=temp, alpha=0.5)
g.map_lower(sns.regplot, data=temp, scatter=False, color=sns.color_palette("rocket")[3])
g.map_lower(corrdot)
g.map_upper(hide_current_axis)
g.map_diag(sns.histplot)
<seaborn.axisgrid.PairGrid at 0x1ac592bf340>
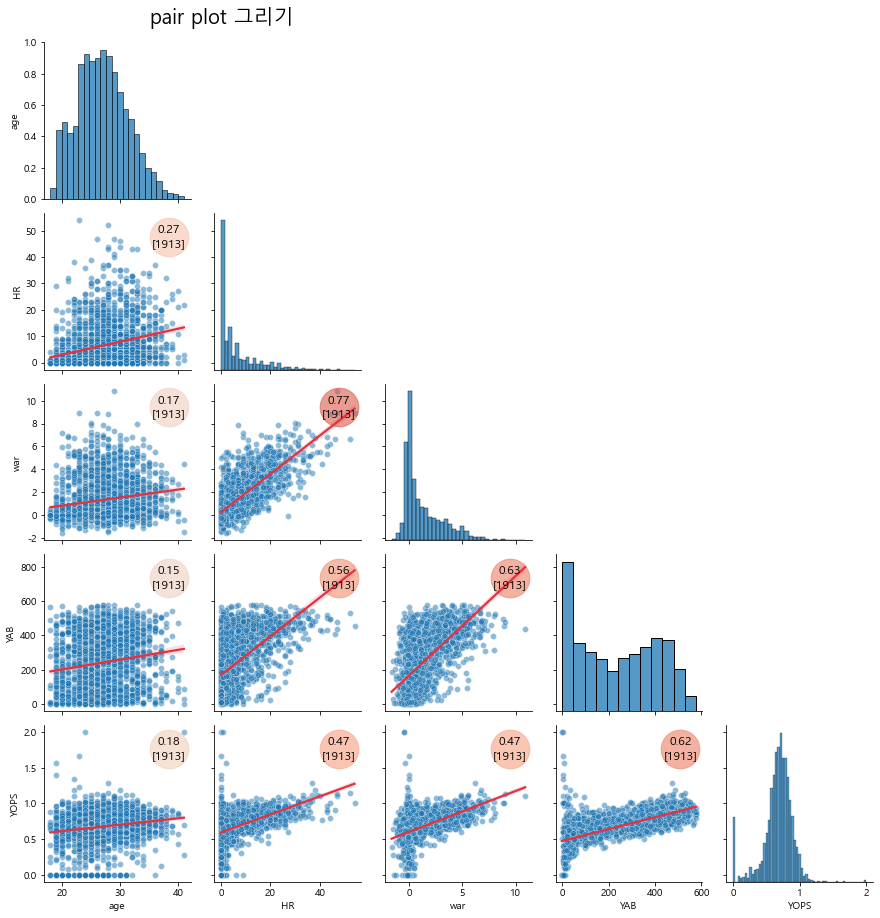
마지막으로 x축과 y축의 컬럼의 크기를 조절하는 방법을 소개하려고 합니다.
plotting_context에서 axes.labelsize는 말 그대로 축의 라벨 사이즈를 조절하는 방식입니다.
해당 방식을 통해 전보다 축에서의 컬럼 크기가 늘어난 것을 볼 수 있습니다.
with sns.plotting_context(rc={"axes.labelsize":15}):
temp = data[['age','HR','war','YAB','YOPS']]
g = sns.PairGrid(temp, diag_sharey=False)
g.fig.suptitle("pair plot 그리기", x=0.25, y=1.02, size=20)
g.map_lower(sns.scatterplot, data=temp, alpha=0.5)
g.map_lower(sns.regplot, data=temp, scatter=False, color=sns.color_palette("rocket")[3])
g.map_lower(corrdot)
g.map_upper(hide_current_axis)
g.map_diag(sns.distplot)