python plotly 소개 및 radar chart 그리기
python plotly 소개 및 radar chart 그리는 법을 소개하려 합니다.
해당 코드를 실습할수 있는 데이터는
캐글 데이터 페이지를 통해서 다운로드 부탁드리겠습니다.
import warnings
warnings.filterwarnings(action='ignore')
import numpy as np
import pandas as pd
from pandas import DataFrame
import math
import seaborn as sns
%matplotlib inline
import matplotlib.pyplot as plt
data = pd.read_csv("2019_kbo_for_kaggle_v2.csv")
print(data.shape)
data.head(2)
(1913, 37)
| batter_name | age | G | PA | AB | R | H | 2B | 3B | HR | ... | tp | 1B | FBP | avg | OBP | SLG | OPS | p_year | YAB | YOPS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 백용환 | 24.0 | 26.0 | 58.0 | 52.0 | 4.0 | 9.0 | 4.0 | 0.0 | 0.0 | ... | 포수 | 5.0 | 6.0 | 0.173 | 0.259 | 0.250 | 0.509 | 2014 | 79.0 | 0.580 |
| 1 | 백용환 | 25.0 | 47.0 | 86.0 | 79.0 | 8.0 | 14.0 | 2.0 | 0.0 | 4.0 | ... | 포수 | 8.0 | 5.0 | 0.177 | 0.226 | 0.354 | 0.580 | 2015 | 154.0 | 0.784 |
2 rows × 37 columns
이번에 소개해드릴려고 하는 것은
간단하게 그릴 수 있는 시각화 라이브러리인 matplotlib과 seaborn과는 다르게
동적으로 값을 바로 볼 수 있고, 또한 추가적인 조작을 통해서 자세히 볼 수 있게 해주는
plotly 라이브러리를 활용한 radar chart 그리기 입니다.
radar chart는 아래와 같은 차트로
주로 여러 컬럼을 평가 항목으로 두고, 이를 이은 형태를 가지고 있습니다.
이를 위해서 주로 수치를 통일해주는 과정이 필요합니다.
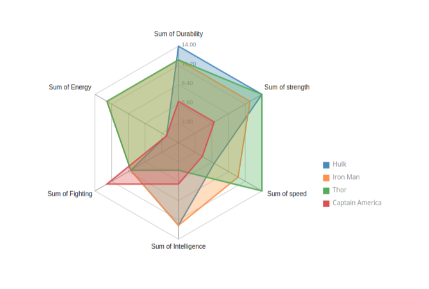
이 차트는 주로 여러 항목을 정량화해두고 이를 그룹간 비교를 하기에 용이합니다.
다만, 이게 저 상태 그대로만 있다면 4개 그룹간 비교만 가능합니다.
그리고 보통 값이 한쪽에만 표시가 되기 때문에, 다른쪽에 있는 값을 보기에는 불편합니다.
그렇기에, 저는 radar chart를 그려야될 때가 있으면, 무조건 plotly를 사용하는 편입니다.
plotly와 두 라이브러리의 가장 큰 차이점은 plotly는 마우스 커서에 따라 값이 바로 확인 가능 하다는 점입니다.
그리고 그룹을 미리 지정을 해두었다면, 이 범례들을 클릭하면서 넣었다 뺐다 자유롭게 가능합니다.
그럼 이를 자세하게 보실 수 있게,
이번 야구 데이터에서 SPD라는 speed value의 5가지 스탯의 평균 값을 통해 보여드릴려고 합니다.
- f1(도루 성공률) = ( ( SB + 3 ) / ( SB + CS + 7 ) – 0.4 ) * 20
- f2(도루 시도율) = ( ( SB + CS ) / ( ( H – 2B – 3B – HR ) + BB + HP ) )^0.5 / 0.07
- f3(3루타 비율) = 3B / ( AB – HR – K ) / 0.02 x 10
- f4(출루 시에 득점 비율) = ( ( R – HR ) / ( H + BB – HR – HP ) - 0.1 ) / 0.04
f5(병살 회피율) = ( 0.055 – GDP / ( AB – HR – K ) ) / 0.005
- 각 성분(f1~f5)은 최소 0, 최대 10으로 조정한다.
DataFrame(f1~f5).hist()를 통해서 inf가 있는 것을 수정하고,
값이 크거나 0 미만의 값이 나오면 0이 되도록 수정하였습니다.
원래라면 spd 값 자체를 야구 통계 사이트를 통해서 가져오는 것이 제일 좋으나,
SPD를 이루는 5개의 값들로 그림을 그리기 위해 임의로 이상치 처리 작업을 진행 하였습니다.
regular3 = data.copy()
f1 = list( (((regular3['SB']+3)/(regular3['SB']+regular3['CS']+7))-0.4) * 20 )
f2 = list( (((regular3['SB']+regular3['CS'])/(regular3['H']-regular3['2B'] -
regular3['3B']-regular3['HR']+regular3['BB']+regular3['HBP']))**0.5) / 0.07 )
f3 = list( ((regular3['3B']/(regular3['AB']-regular3['HR']-regular3['SO']))/0.02)*10 )
f4 = list( ((regular3['R']-regular3['HR'])/(regular3['H'] +
regular3['BB']-regular3['HR']-regular3['HBP'])-0.1)/0.04 )
f5 = list( (0.055-(regular3['GDP']/(regular3['AB'] -
regular3['HR']-regular3['SO'])))/0.005 )
f1 = DataFrame([0 if ii < 0 else ii for ii in f1])
f2 = DataFrame([0 if ii == math.inf else ii for ii in f2])
f3 = DataFrame([0 if ii >= 20 else ii for ii in f3])
f4 = DataFrame([0 if (ii == math.inf) | (ii>=40) | (ii<0) else ii for ii in f4])
f5 = DataFrame([0 if ii < 0 else ii for ii in f5])
그리고 SPD에서의 설명에 따라 0~10의 값으로 최적화를 진행해 줍니다.
애초에 과정은 radar chart에서 각 컬럼들의 범위가 다를 경우,
어느 한 컬럼은 값이 크게 나오고, 어느 한 컬럼은 작게 나오기 때문에 값의 범위를 통일해 주시는 것이 좋습니다.
# 각 값들은 0~10사이의 값을 가져야 되므로 값 최적화 과정을 해줌
f1 = ((f1-f1.min())/(f1.max()-f1.min()))*10
f2 = ((f2-f2.min())/(f2.max()-f2.min()))*10
f3 = ((f3-f3.min())/(f3.max()-f3.min()))*10
f4 = ((f4-f4.min())/(f4.max()-f4.min()))*10
f5 = ((f5-f5.min())/(f5.max()-f5.min()))*10
그리고 선수 이름에 맞춰 값을 채워주고, 빈 부분을 0으로 채워줍니다
그러한 다음, groupby를 통해 선수별 평균 값으로 바꿔줍니다.
f_total=pd.concat([regular3['batter_name'],f1,f2,f3,f4,f5],axis=1)
f_total=f_total.fillna(0) #비어있는 부분을 0으로 채움
f_total.columns = ['batter_name'] + list(range(0,5))
f_group=f_total.groupby(['batter_name'])[0,1,2,3,4].mean() #각 선수마다의 f1 ~5 평균값을 계산
이번 목표가 선수마다 각 SPD 항목 중, 가장 우수한 항목이 있을 것이니
이를 그룹화하여서 radar chart로 그리는 것을 목표로 하였기에,
각 선수마다 f1 ~ f5 중 최대값을 해당 그룹으로 배정해두었습니다.
ind = []
for i in range(len(f_group)):
# 각 선수의 f1 ~f5 항목 추출
test = f_group[0][i], f_group[1][i], f_group[2][i], f_group[3][i], f_group[4][i]
ind.append(test.index(max(test))) # 선수 마다 f1 ~ f5중 가장 높은 항목으로 그룹화 진행
f_group['group'] = ind
f_group['group'].value_counts()
4 275
0 32
3 21
2 7
1 3
Name: group, dtype: int64
병살회피율 그룹인 4번에 대부분이 몰려있지만,
애초에 plotly와 radar chart를 보여드리기 위함이었므로 넘어가도록 하겠습니다.
그리고 이 상태로 그리게 되면, 선수 약 300명에 대해서 그려지게 되므로
각 그룹별 컬럼에 대한 평균 값을 구하고,
그 중에서 제일 높은 컬럼의 최대값으로 나눈 다음
10을 곱하여서 10점 지표로 변경하였습니다.
# f1이 높은 그룹의 f1 ~ f5 평균값을 계산하는 방식을
# f1~f5에 적용시키고 이후 radar chart의 시각화 값으로 사용함
f11 = (f_group.loc[f_group['group'] == 0, [0, 1, 2, 3, 4]].mean()) / \
max(f_group.loc[f_group['group'] == 0, [0, 1, 2, 3, 4]].mean()) * 10
f22 = (f_group.loc[f_group['group'] == 1, [0, 1, 2, 3, 4]].mean()) / \
max(f_group.loc[f_group['group'] == 1, [0, 1, 2, 3, 4]].mean()) * 10
f33 = (f_group.loc[f_group['group'] == 2, [0, 1, 2, 3, 4]].mean()) / \
max(f_group.loc[f_group['group'] == 2, [0, 1, 2, 3, 4]].mean()) * 10
f44 = (f_group.loc[f_group['group'] == 3, [0, 1, 2, 3, 4]].mean()) / \
max(f_group.loc[f_group['group'] == 3, [0, 1, 2, 3, 4]].mean()) * 10
f55 = (f_group.loc[f_group['group'] == 4, [0, 1, 2, 3, 4]].mean()) / \
max(f_group.loc[f_group['group'] == 4, [0, 1, 2, 3, 4]].mean()) * 10
f_num_total = pd.concat([f11,f22,f33,f44,f55],axis=1)
f_num_total.columns = ['도루 성공율','도루 시도율','3루타 비율',
'출루시 득점 비율(홈런 제외)', '병살 회피율']
f_num_total['best'] = f_num_total.columns + ' 우수 그룹'
f_num_total
| 도루 성공율 | 도루 시도율 | 3루타 비율 | 출루시 득점 비율(홈런 제외) | 병살 회피율 | best | |
|---|---|---|---|---|---|---|
| 0 | 10.000000 | 5.113024 | 2.959596 | 2.962613 | 3.347760 | 도루 성공율 우수 그룹 |
| 1 | 3.470671 | 10.000000 | 2.352221 | 1.992922 | 1.939638 | 도루 시도율 우수 그룹 |
| 2 | 3.483240 | 0.000000 | 10.000000 | 0.592877 | 1.606974 | 3루타 비율 우수 그룹 |
| 3 | 4.154623 | 1.002238 | 4.130760 | 10.000000 | 3.133935 | 출루시 득점 비율(홈런 제외) 우수 그룹 |
| 4 | 7.374489 | 0.850384 | 6.577645 | 4.367828 | 10.000000 | 병살 회피율 우수 그룹 |
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
categories = list(f_num_total.columns[:-1]) + [f_num_total.columns[0]]
fig = go.Figure()
for jjj in range(f_num_total.shape[0]):
fig.add_trace(go.Scatterpolar(
r = list(f_num_total.iloc[jjj][:-1]) + [f_num_total.iloc[jjj][0]],
theta = categories,
#fill = 'toself',
name = f_num_total.iloc[jjj][-1]
))
fig.update_layout(polar=dict(
radialaxis=dict(
visible=True, range=[0,10])
), showlegend=True,
)
fig.show()
