추천시스템 기본 정보
추천시스템에 대한 기본 정보를 남긴 포스팅 입니다.
필터링 method
Contents-Based Filtering(컨텐츠 기반 필터링) :
말 그대로 컨텐츠 기반의 추천 알고리즘
TF-IDF, Word2Vec, Similarity 활용하여
사용자가 로맨스 영화에 높은 평점을 좋았으면 다른 로맨스 영화를 추천해주는 단순한 방식
장점 : 콜드 스타트 문제 해결 가능
단점 : 메타 정보의 한정성, 개인 성향 세부적 파악 어려움
Collaborative Filtering(협업 필터링) :
아이템 평점, 상품 구매 이력 등 “사용자 행동 양식” 기반 추천
A. Memory-Based Approach
user based(사용자 기반) : 비슷한 취향 사람들의 이웃 선택 (평점 유사도 기반)
item based(아이템 기반) : 특정 item 선택 -> 사용자들이 공통적으로 좋아한 다른 item 찾음
방법 : Cosine Similarity, Pearson Correlation 등
장점 : 쉽게 생산 & 결과 설명력 좋음 & 도메인 의존적 x
단점 : 데이터 축적 x or Sparse 한 경우 성능이 낮음 & 확장 가능성 적음
(+ 데이터 너무 많으면 속도 저하 됨.)
B. Non-Parametric(비모수적) Approach
Memory-based는 사용자, 아이템 유사도를 사용.
가중치 평균 사용하여, 사용자의 아이템 평가를 예측함.
단, 여기서는 Unsupervised Learning 모델을 사용함.
(ex - KNN은 k개의 이웃한 사용자 수로 제한하여, 시스템 확장성을 높일 수 있음.)
C. Model-Based Approach
특징 : 기계학습 이용 & 최적화 방법 or 매개변수를 학습
방법 : “행렬 분해(Matrix Factoriztion)”, SVD, 신경망 모델
장점 : Sparse한 데이터 처리 가능, 초기 모델 구축 후 Inference도 쉽게 가능.
단점 : 결과 설명력 낮음, 초기 모델 Training 연산이 오래 걸림
- cf. 행렬 분해(Matrix Factoriztion)
관련 tutorial -> 정리한 github repository (실습 후 정리 필요)
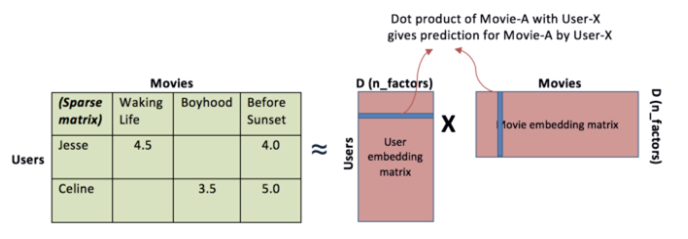
user, item 모두에 대해 5차원 임베딩이 있다고 가정
-> 해당 User-Item 행렬을 User-X, Item-A 행렬로 변환.
(변환 방법은 : SVD, NMF(비음수 행렬 분해), PMF 등 존재함.)
단, 실제 각 Factor가 무엇을 의미하는지는 정확히 확인 불가
but 각 행렬의 내적값이 높을 수록 User-X에게 Movie-A가 더 좋은 추천 가능함.
장점 : 선형적 곱하는 단순한 방법으로 매우 효율적임.
단점 : User, Item 사이의 복잡한 비 선형적 상호관계를 모델링 하기에는 불충분할 수 있음.
- 해결안 1. 더 높은 차원의 latent space 도입 (축 1개 추가) 하면 더 복잡한 표현 가능
-> 그럼 모델의 일반화 성능이 저해 됨. -> 비추천
- 해결안 2. 비선형적 관계 모델링이 가능한 신경망 활용 시, 복잡한 상호 관계 적용 가능.
- cf2. NMF(Non-negative Matrix Factorization)
음수를 포함하지 않는 행렬 X를
음수를 포함하지 앟는 행렬 W, H의 곱으로 분해하는 알고리즘
(learning rate를 data-driven한 방법을 이용해 정의하고,
이를 이용하여서 Gradient Descent를 하게 되므로
W, H 행렬은 음수가 나타나지 않는다.)
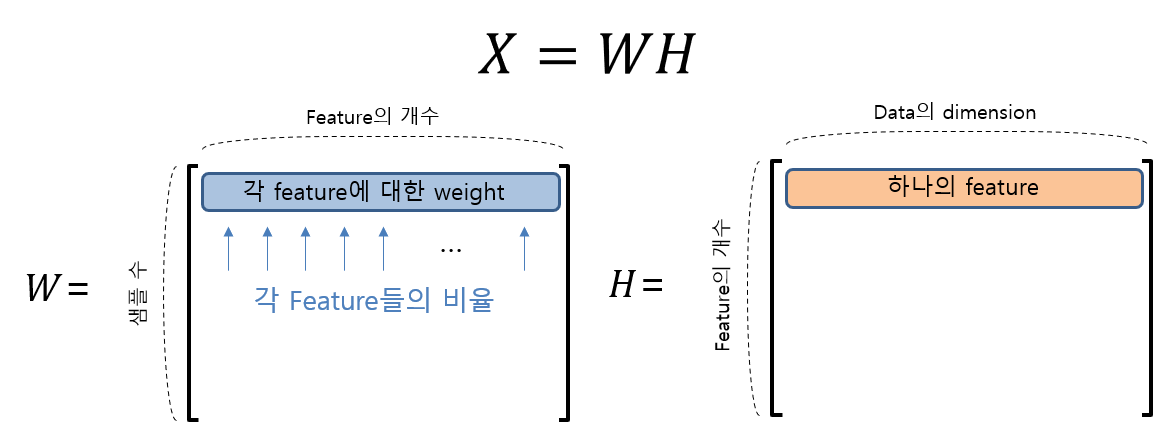
(X = WH) (X는 m x n 행렬)
W의 한 행은 각각의 feature들을 얼마나 섞어 쓸지의 weight. (열은 feature의 갯수)
H의 각 행은 하나의 feature (열은 data의 dimension)
유용한 이유 :
A. 다른 matrix factorization 방법들은 획득 되는 feature들이 음수이면 안된다는 보장이 없다.
-> non-negative한 데이터를 설명하는데에는 있어,
non-negative한 feature로 설명하는 것이 제일 좋음.
(ex - pixel의 세기로 구성된 이미지 데이터)
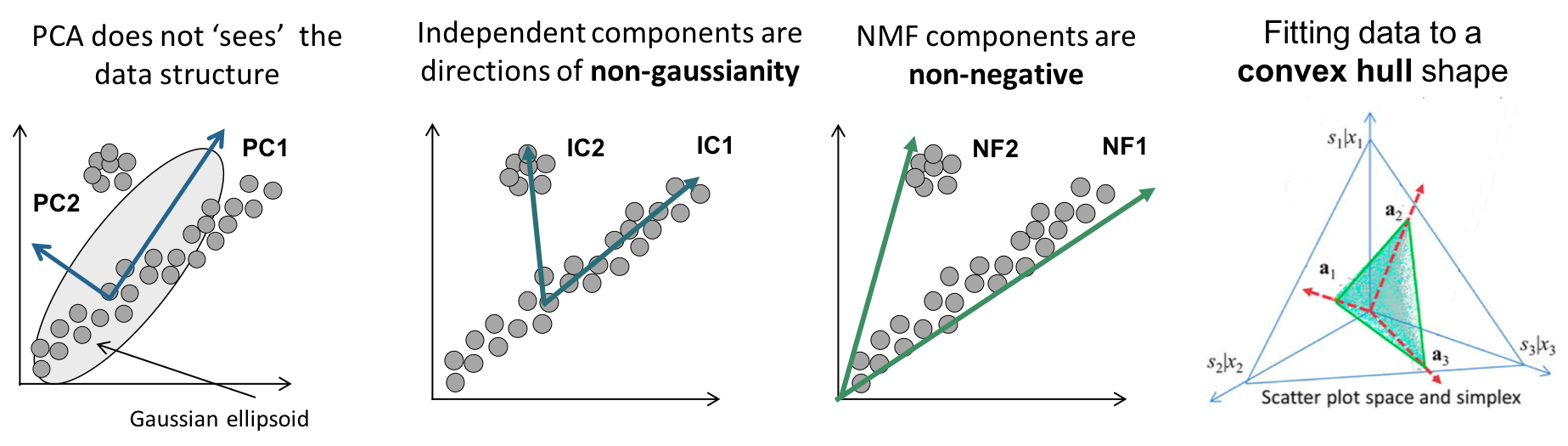
B. 타 기법에 비해 feature들의 독립성을 잘 catch함.
(PCA나 SVD는 설계 구조가 feature 간 직교성을 보장하는 알고리즘)
(이유 : PCA는 covariance matrix가 symmentric matrix
-> eigenvector들이 항상 직교함.)
feature 벡터들이 서로 직교하게 되면, 데이터셋의 실제 데이터 구조를 잘 반영하지 못할 수 있다.
- cf3. PMF(Probabilistic Matrix Factorization)
데이터 셋에서 원소들이 특정 분포를 따른다는 전제하에
확률적인 방법으로 예측값을 추정하는 방법.
(Bayesian rule, “MAP Estimation” 등 사용)
성능적 단점 : 사용자 간 관계를 고려하지 않고,
user x item 행렬만을 이용해서 예측함.
- MAP Estimation 관련 ex
어떤 길이의 머리키락이 나올 때, 그 머리카락의 성별을 판단하는 문제.
MLE : 남자/여자에게서 해당 길이의 머리카락이 나올 확률을 각각 비교하여 가장 확률이 큰 성별 선택
MAP : 머리카락이 발견 되었을 때, 그 머리카락이 남자일 것의 확률, 여자일 것의 확률을 비교해서 더 큰 값을 갖는 성별을 선택하는 방법.
“즉, 사후확률을 최대화시키기는 방법”
D. 협업 필터링 한계점
1.콜드 스타트(Cold Start)
데이터가 중요함.(User-Item 행렬이 충분히 구축 되어야 함.)
user-based : 신규 사용자 행동 기록 없으면, 어떠한 아이템도 추천 x.
item based : 신규 상품이 출시 되더라도 추천 x.
-> 시스템이 충분한 정보를 갖고 있지 않다면 추천 불가함.
2.계산 효율성 저하
사용자가 많아질수록 계산 시간 증가. 근데 사용자가 많아야지 정확한 추천 결과가 나타남.
3.Long-Tail 문제
파레토 법칙 (전체 결과의 80%가 전체 원인의 20%에서 발생되는 현상)
-> 사용자들이 관심 가지는 소수 인기 콘텐츠를 주로 추천함.
-> 품질 좋은 아이템은 추천되지 못하고 “추천의 다양성”이 떨어짐.
