5회 빅데이터분석기사 필기 & 실기 후기
5회 빅데이터분석기사 필기 & 실기 합격 후기 입니다.
21년도에 나와서 이제 5회차 (사실은 4회인) 빅데이터 분석 기사입니다.
기본 정보처리기사만 있던 때보다는 데이터 분석 쪽 분들이
만약 기사 자격증이 필요하시다면 취득하기 유리하다고 생각합니다.
비슷한 분석 자격증으로 ADP가 있는데
있다고 해서, 나는 데이터 분석을 엄청 잘해!
난 진짜 전문가가 됬어! 취업 잘 되겠지?
이런게 아닌 분야이기 때문에 ADP는 무리해서 얻을 필요는 없다고 생각합니다.
여담이지만 최근에 분석쪽 자격증 블로그를 보다
ADP 실기 강의에 100만원이나 쓰셨다고 해서 놀랐습니다…
다시 돌아와서 분석기사 링크 이동하시면
필기도 있고 실기도 있습니다.
두 곳 보면서 정리 했습니다.
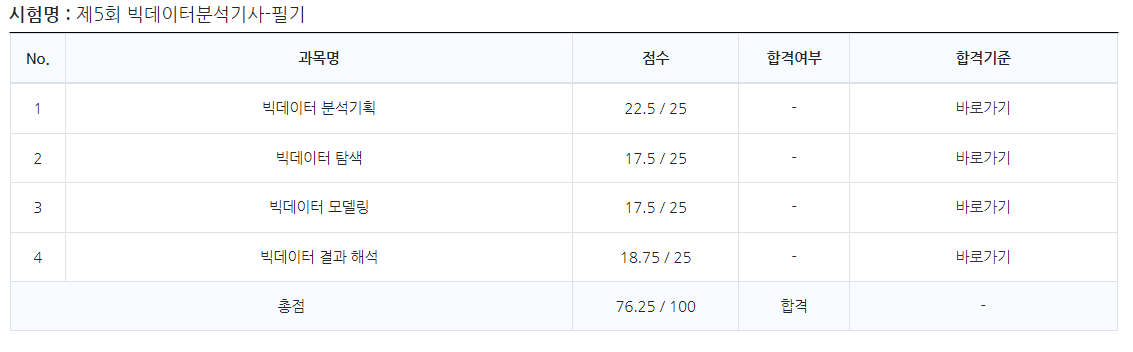
통계쪽 이론 지식이 있어서 괜찮긴 했는데 생각보다 보실게 많습니다.
문제도 합치면 80개가 되다보니 기출문제들 푸시다가
많이 보이거나 헷갈리시는 문제는 나올 수도 있다고 생각하시는 편이 좋다고 생각했습니다.
실기 같은 경우는 필기 합격 이후에 바로 보실 수 있게 되어있어서
필기 합격 후에 바로 준비하시는 것이 가능합니다.
(ADP는 필기 합격 발표 전에 같은 회차 실기 접수를 받아서 안됩니다…
24년부터는 연 2회로 바뀌어서 안 그럴수 있지만 혹시 모릅니다…)
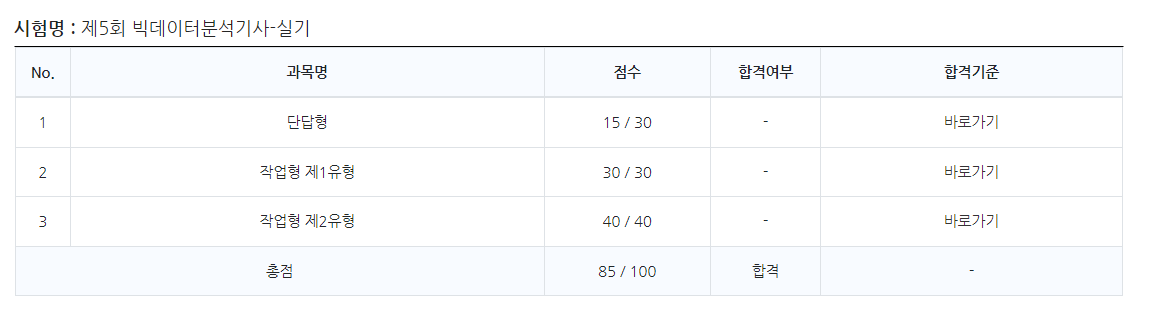
실기는 총 180분에 90분 이후 퇴실이 가능합니다.
단답형 10문제, 작업형1(데이터 전처리),
작업형2(모델링 - 분류, 회귀)로 나뉘는데
모두 온라인으로 봅니다.
그리고 제일 중요한 것이 고사장 환경이
어느 학원을 빌려서 하는 경우가 많기에,
응시 하시기 전에 실기 후기들 보고 하시는걸 추천합니다.
저 같은 경우는 더조은아카데미 강남이었는데 무난한 편이었습니다.
시험장 환경 같은 경우는
응시환경테스트 을 해보시는걸 추천합니다.
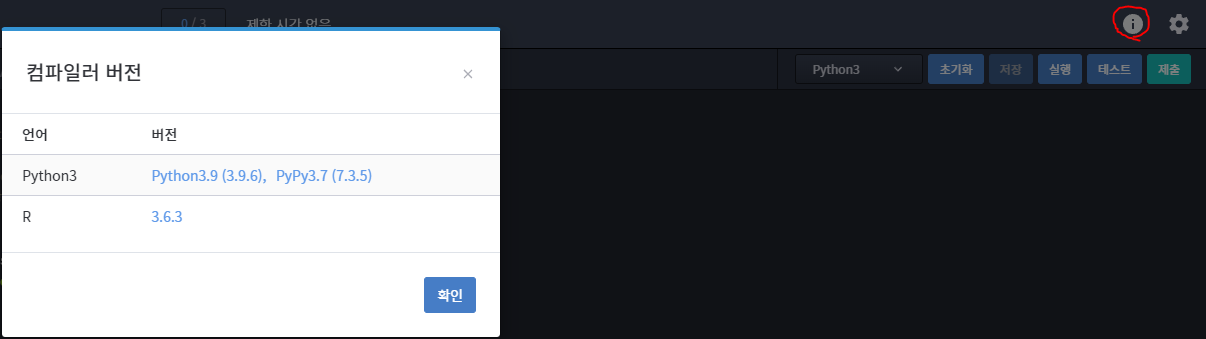
단 작업형에 오른쪽 위에 있는 컴파일러 버전에 나오는
파이썬 공식 문서는 시험 시 제공되지 않습니다.
제공되는건 오직 파이썬 라이브러리와 문제 제출 방식, 컴퓨터 빈 메모장입니다.
대부분 패키지를 import 할 것이기에 주로 불러와야 될 것들은
기억 해가시는걸 추천합니다.
import sklearn
물론 print(help(sklearn)) 방법으로 추가 세부 내역을 보실 수 있습니다.
오픈북이 아니기 때문에 해당 방법으로 보셔야지
세부 구문 까먹으셔도 import 하시기 편합니다.
만약에 시험을 준비하고 계신다면 캐글준비사이트 를 추천합니다.
작업형2는 데이터만 다르지 대부분 푸는 순서는 비슷합니다.
작업형1의 경우는 코드는 짧은 경우가 많지만, 문제를 잘 읽어보셔야지 됩니다.
그리고 단답형 같은 경우는 필기 공부하신거 참고하시면 될 듯합니다.
그리고 rmse, f1_score 같은 경우는 작업형 환경에서 구현이 가능합니다.
f1_score는 어떤게 True Positive 인지 잘 확인하면서 구현하셔야 합니다.
간단한 예시를 보여드리며 마치겠습니다.
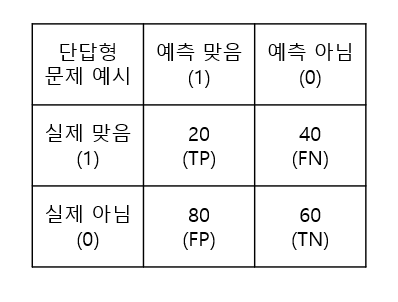
–> 정답 F1_score : 0.25
point : TP(예측/실제 모두 긍정인 경우) 가 왼쪽 위에 있음.
from sklearn.metrics import f1_score, precision_score, recall_score
from sklearn.metrics import confusion_matrix
오답
list1 = [0]*20 + [1]*60 + [0]*40 + [1]*80
list2 = [0]*20 + [1]*60 + [1]*40 + [0]*80
confusion_matrix(list1, list2)
array([[20, 40],
[80, 60]], dtype=int64)
precision_score(list1,list2), recall_score(list1,list2), f1_score(list1,list2)
(0.6, 0.42857142857142855, 0.5)
정답
list1 = [1]*20 + [2]*60 + [1]*40 + [2]*80
list2 = [1]*20 + [2]*60 + [2]*40 + [1]*80
confusion_matrix(list1, list2)
array([[20, 40],
[80, 60]], dtype=int64)
precision_score(list1,list2), recall_score(list1,list2), f1_score(list1,list2)
(0.2, 0.3333333333333333, 0.25)
