Tabnet 논문 해석하기
Tabnet 논문을 자세히 들여보다보고 작성합니다.
Tabular(정형) 데이터를 위한 딥러닝 모델이라고 소개가 된,
2019년 구글의 Tabnet 입니다.
해당 포스팅에서는 Tabnet 논문의 내용 중 성능 측정을 제외한
개요 및 장점, 하이퍼 파라미터 규칙 등에 대해서 작성하려고 합니다.
구조의 경우 다음 포스팅에서 따로 다루도록 하겠습니다.
논문을 보는데 참고한 사이트들 출처도
구조 포스팅에서 마지막에 기입 하도록 하겠습니다.
먼저 Tabnet을 리뷰하고 사용하면서 생각한 사항들을
간단히 요약 하자면 다음과 같습니다.
a. 데이터가 많고, 이미지 등 여러 타입이 있으며,
모델 갱신이 자주 되어야 때 유용.
b. 사용 결과, 논문처럼 ML보다 우수한 정도는 아님.
c. 성능은 비슷하거나 낮을때도 있고, 시간은 훨씬 오래 걸림
d. 일반 정형 데이터라면, 다른 ML모델을 쓰거나 같이 앙상블 하는 정도를 추천함.
e. hyperparamter tuning의 경우, default 설정으로도 충분.
1.Introduction
먼저 딥러닝이 이미지, 텍스트, 음성 등에서 빠른 성과가 나오고 있지만
정형 데이터에서는 이러지 못하는 이유를 소개하고 있습니다.
논문에서는 주요 이유는 Tree 계열 모델이
정형 데이터에 더 적합한 이유를 나열 하였습니다.
a. 정형 데이터는 Hyperplane(초평면) 경계를 가지는
Manifold에서 결정을 할 때, 더 효울적으로 작동
(결정 기준이 DL보다 더 적합)
b. 학습이 더 빠르고, 더 쉽게 개발 가능
c. 높은 해석력을 가지고 있음.
Tree 모델의 변수 중요도 -> 딥러닝 보다 해석이 더 용이함
& DL모델은 Overparameterized 되어 사용에 적합하지 않음.
위에서 언급된 것 처럼 Tree 계열 모델
그 중에서도 부스팅 계열의 모델(XGB, LGB, CatBoost 등)은
kaggle의 정형 데이터 분석에서도 자주 사용 되고
빠르게 결과물을 내 놓을 수 있습니다.
하단에 kaggle의 대회 중, 상금은 없지만
꾸준히 개최 되는 중인 kaggle playground의 링크를 추가하였습니다.
Kaggle Playground 23년 시즌1, Kaggle Playground 23년 시즌2, Kaggle Playground 22년 8월
물론 상위권 리더보드를 보면 복잡한 딥러닝 층으로 concat을 하는 방식으로
수행하는 경우도 있지만, AutoML을 사용하거나,
여러 ML 모델을 concat해서 결과 도출을 합니다.
새로운 ML모델이 나오기 보다는, 기존 모델들의 앙상블 만으로도
상위권의 성적이 나올 수 있게 할 수 있다는 것을 의미 한다고 생각합니다.
그럼 다시 논문으로 돌아와서, Tree모델은 확실히 현재 Trend를 봐도
우수한 성능을 보이고, 빠르게 결과 도출을 하는 것이 가능합니다.
그럼에도, 딥러닝을 사용 하여야 되는 이유도 같이 서술하고 있습니다.
a. 데이터가 많을때, 계산 비용이 높아져도 성능의 향상이 가능하다.
b. 이미지 등 다른 데이터 타입과 함께 학습 가능,
& 필수적인 Feature Engineering 요구하지 않음
c. Streaming data로 부터 학습 용이 & end-to-end model 구조
즉, 데이터가 많고 여러 데이터 타입이 사용 되면서
모델의 갱신이 자주 되는 경우에는 머신러닝보다
이번에 발표하는 Tabnet 사용을 추천하는 것입니다.
위에서 언급 된 Tabnet(딥러닝)을 사용하여야 되는 이유와
가장 잘 맞는 넥슨의 테크 블로그 포스팅 이었습니다.
Intro 마지막에는 Tabnet을 사용할 때의 장점도 소개하고 있습니다.
a. raw data 로 end-to-end learning이 가능하다.
(soft feature selection이 모델 안에 적용 되어 있음.)
b. sequential attention 사용으로 각 step 마다 중요 feature 선별
-> 모델 해석, 성능 향상 가능
c. 다양한 도메인, 다른 모델 비교시에 성능이 우수함
d. Masking된 feature 예측 시,
비지도 학습을 진행해서 우수한 성능을 도출해냄
결론적으로는, 어떤 도메인이든, 데이터 처리 따로 안해도
우수한 성능을 낼 수 있는 Tabnet이라는 이야기 입니다.
정말 우수한지는 논외로 치고 다음 파트로 넘어가겠습니다.
2.Related Work
먼저 feature selection 방식입니다.
Trainable Mask(dense한 mask가 아닌 sparse mask 사용)로
Sparse Feature selection(feature에 가중치를 부여) 을 하는 것이라고 합니다.
말이 어렵긴한데, feature selection 기능을 넣기 위해
기존 mask가 아닌 sparsemax라는 활성화 함수로 만든
mask를 사용하였다는 것입니다.
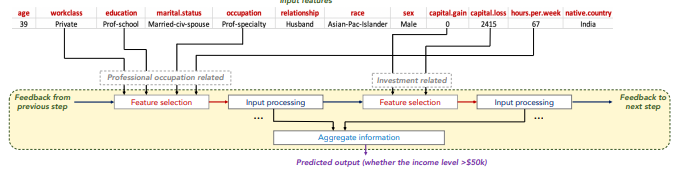
예시에서는 39세의 income을 예측하는 것인데,
첫 selection에서는 직업 관련 변수들,
두번째 selection에서는 투자 관려뇐 변수들이 선택되어서
학습되는 것을 소개하였습니다.
다음은 Convolution DNN 입니다.
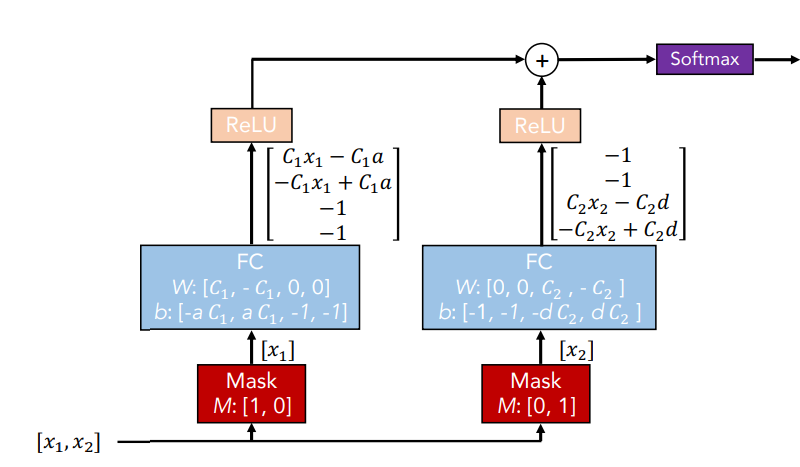
좌측 mask block은 첫 번째 변수만 학습에 활용하고
우측 mask는 두 번째 변수만 학습에 활용하게 하는 방식입니다.
즉 선택되지 않은 나머지 변수들에는 0으로 마스킹을 합니다.
그렇기에 FC 네트워크에서는 하나의 변수만 활용되게 하는 것입니다.
3.Guidelines for hyperparameters
구조는 앞서 언급 한 것 처럼 따로 포스팅을 작성 하였습니다.
마지막 파트 중 Ablation studies는
test accuracy를 최우선해서 base를 설정한 것이 요지였습니다.
Nd = Na = 64, γ = 1.5, Nsteps = 5, λsparse = 0.0001로 되어있고
feature transformer의 4개 블록의 역할을 2, 2로 나누어서 구성 했으며
Batch size는 16284 (2**14) 입니다.
저도 실제 사용 결과, hyperparamter 튜닝을 하기 보다
기본 base만 사용을 해도 될 정도 성능이 괜찮았습니다.
하지만, 모든 데이터가 base가 최적일 순 없으니,
논문에서는 guidelines를 제시하였습니다.
a. Nd = Na 로 두 값이 동일하게 설정을 하는 것을 추천 한다.
해당 값이 매우 높을 경우, 과적합이 발생하고 일반화에 적합하지 않을 수 있다.
b. N-steps의 경우 3~10이 적절하다.
정보를 포함한(information-bearing) features가 많을수록
N-steps도 커지는 경향이 있다.
단, 이 값이 높아지만 과적합 발생과 일반화에 부적합할 수 있다.
c. γ 은 성능에 중요한 역할을 하며,
N-steps가 클 경우, 더 큰 γ 값을 선호로 한다.
d. batch-size는 큰 것이 좋다.
메모리 문제가 있다면 전체 데이터의 1~10% 정도로 설정하는 것이 도움이 될 것이다.
e. 초기 learning rate는 크게 잡는 것이 중요하다.
수렴될 때 까지, 서서히 감소한다.
