Tabnet 구조 Part
Tabnet 메인 구조 파트 입니다.
해당 포스팅에서는 Tabnet 논문의 구조에 대해서만 다루었습니다.
간단하게 Tabnet은 기본적으로 encoder를 통해서
학습을 반복하고 이를 FC층에서 합쳐 결과물을 반환합니다.
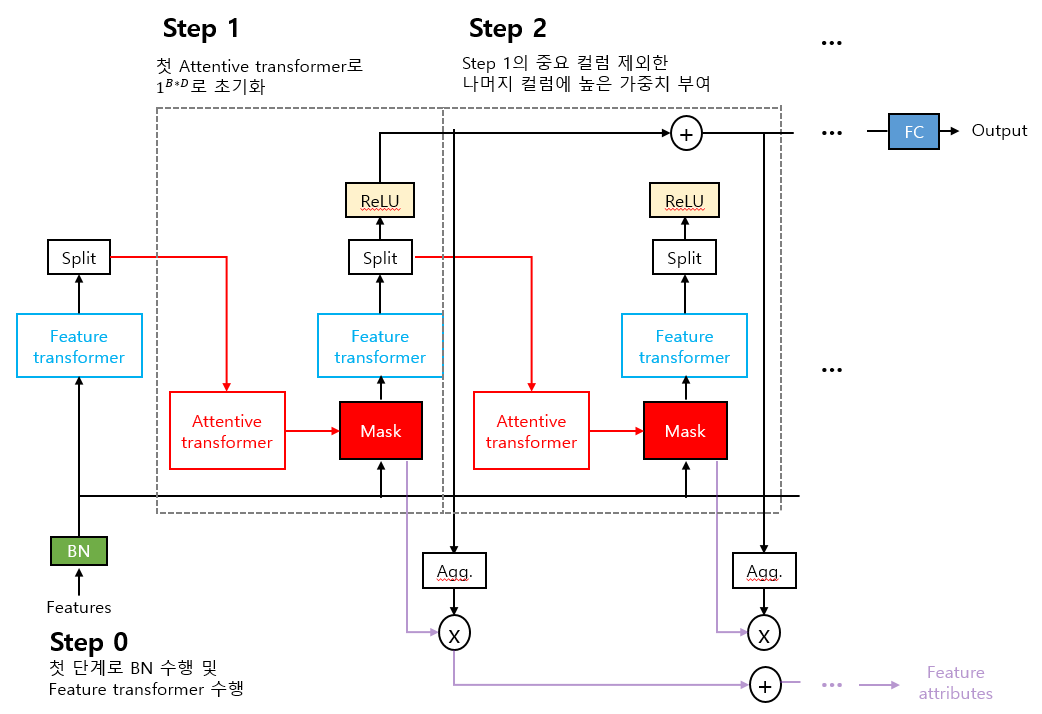
먼저 Encoder architecture입니다.
논문에서의 그림은 step에 칠해진 선 때문에
눈에 잘 안들어와서 새로 만들었습니다.
먼저 데이터가 처음 들어올 때, batch norm을 거칩니다.
output = B * D (입력데이터 차원(feature 수))
그 이후, feature transformer를 통해 임베딩 됩니다.
output = B * A (attention layer 차원)
Attentive transformer를 통해서는
(trainable) Mask가 생성됩니다.
output = B * D(feature 수(일부 컬럼 0 마스킹))
Mask가 생성되면 해당 D차웜 matrix와
첫 feature transformer와 곱합니다.
다시, feature transformer를 통해 임베딩 됩니다.
이번에는 이전 학습 정보가 있기에 output이 다릅니다.
output = B * (A + P) (prediction layer 차원)
이전에 사용 되지 않은 split이 사용됩니다.
B * A -> relu input
B * P -> attentive transformer input
이후는 attentive transformer 파트부터 반복됩니다.
relu의 input은 합쳐져서 FC층을 통과합니다.
output = B * Output 차원 (regression = 1, classification = class 수)
다음으로는 Encoder 중 feature transformer 세부 사항입니다.
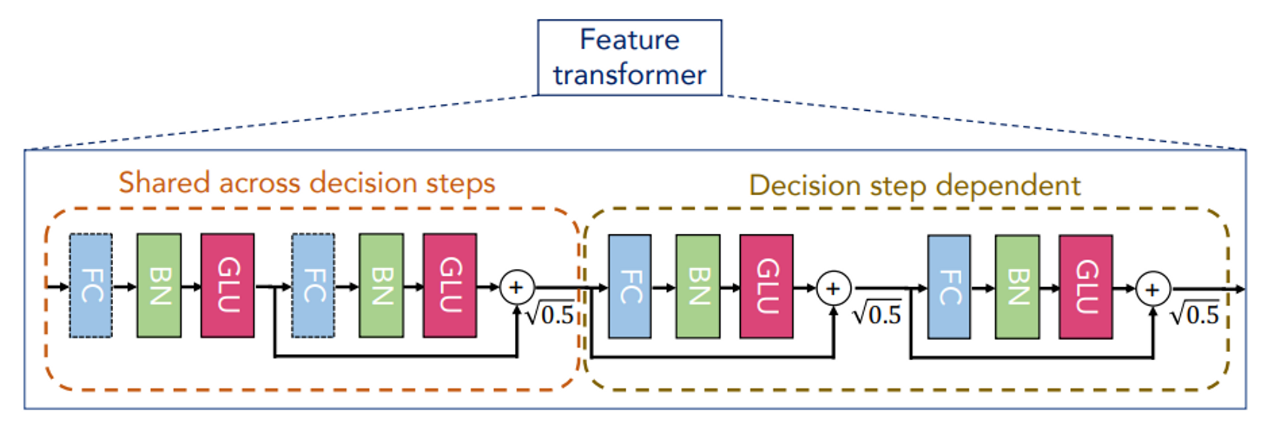
4개의 block 형태로 구성 되어 있으며,
FC -> BN -> GLU(gated linear unit)이 반복 됩니다.
여기서 GLU는 linear mapping 결과물을 A, B 이렇게 둘로 나누어
A는 residual connection,
B는 sigmoid function을 거쳐
element-wise 방식인 비 선형 활성 함수로 계산 합니다.
그리고 앞의 2개 block은 shared block으로
전체 decision step에서 가중치를 공유하며
뒤의 2개 block은 decision block입니다.
각 block 간에는 √0.5 로 정규화 된
skip connection이 존재하여 vanishing gradient 문제를 개선하게 해줍니다.
다음은 attentive transformer 입니다.
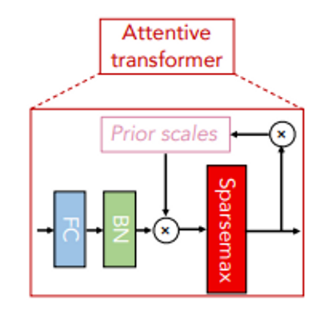
FC -> BN -> sparsemax를 거쳐 mask를 생성합니다.
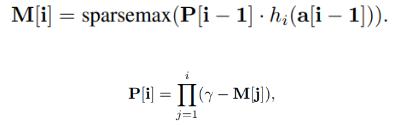
여기서 prior scale term은 이전 step 학습 당시의 정보이며
첫 step에서는 이전 정보가 없기에 1^(𝐵∗𝐷) 로 초기화 되어 있습니다.
만약 데이터에 결측치가 있다면, 해당 부분에는 0으로 초기화가 됩니다.
이러한 이전 정보는 relaxation factor로 조절 가능하며
1로 되어있다면, 하나의 decision step에서만,
이 값이 커진다면, 여러 step에서의 정보도 사용이 가능 합니다.
이러한 정보가 다음 step에서의 mask와 내적하게 되고
이로 인해 step-wise Sparse Feature selection이 가능 해집니다.
mask 파라미터의 경우, loss function이 backpropagation시 업데이트가 됩니다.
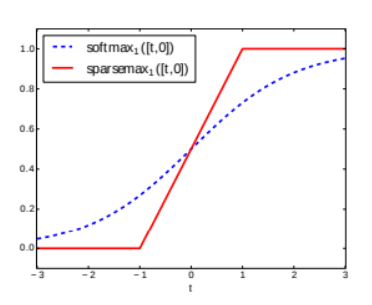
그리고 sparsemax의 경우, softmax의 변형이라고 볼 수 있는데
활성화 함수이기에, 벡터의 합은 1입니다.
softmax보다 극단적인 기울기를 가집니다.
중요한 feature는 1, 아니면 0을 부여하는데,
이러한 1이 되는 구간을 극소화 합니다.
예를 들어 현재 감마가 [1,1] 상태일 때,
이전 중요 컬럼이 첫 번째라면 [1,0] 상태일 것입니다.
[1,1] - [1,0] = [0,1]로 이전 중요 컬럼을 빼주고
이전에 덜 중요한 컬럼에 더 높은 가중치를 부여하는 방식으로
이전 선택 변수의 반영률을 줄여주는 방식으로 학습을 진행 시킵니다.
마지막으로 Decoder입니다.
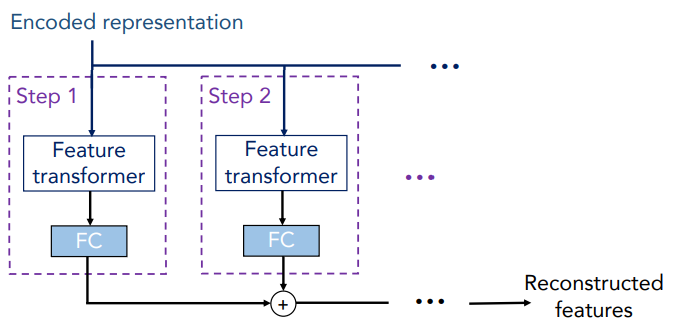
일반적인 분류/회귀에서는 Encoder만 사용되지만,
tabnet은 AutoEncoder같은 자가 학습 구조를 가질 수 있습니다.
Decoder는 각 단계별 feature transformer로 구성 되어 있으며
self-supervised 학습 진행 시, 인코더 다음에 붙어
기존 결측값 보완 및 표현 학습을 진행하게 해줍니다.
참고 출처
